

AIと機械学習とディープラーニングの違い、説明できますか?
ウェブサービスや家電などへの搭載が進み、急速に日常生活の中に溶け込みつつある人工知能(AI)。このAIを語る文脈で「機械学習」あるいは「深層学習(ディープラーニング)」という言葉が頻繁に登場するようになった。でも皆さん、「AI」と「機械学習」と「ディープラーニング」との違いについて、ちゃんと説明できるだろうか?
同じような意味合いで使われるケースも多いこの3つの言葉。でも、それぞれが本来指しているものは実に明確に異なるのだ。
だから例えば「〇〇業向けの業務効率化アプリでは、機械学習を活用してAIを構築しますが、ディープラーニングではないアプローチを採用します」などという文章に出会ったとき、3つの言葉の違いがわかっていないと、何を言っているのやら混乱してしまうに違いない。
そこで今回の科学コラムは、AIに関連する言葉の混乱を少しでも減らせるように、「AI」「機械学習」「ディープラーニング」という三者の違いについて、ざっくり解説していこう。
ディープラーニングは機械学習の一手法、機械学習はAIを構築するためのアプローチのひとつ
まずAIだが、これは人工知能の英語表記である「Artificial Inteligence」の略称だ。つまり一般には「人工知能」と「AI」は同じもの・同じ概念を指していると考えて差し支えない。その上で、AI・機械学習・ディープラーニングの関係性を示したものが次の図だ。
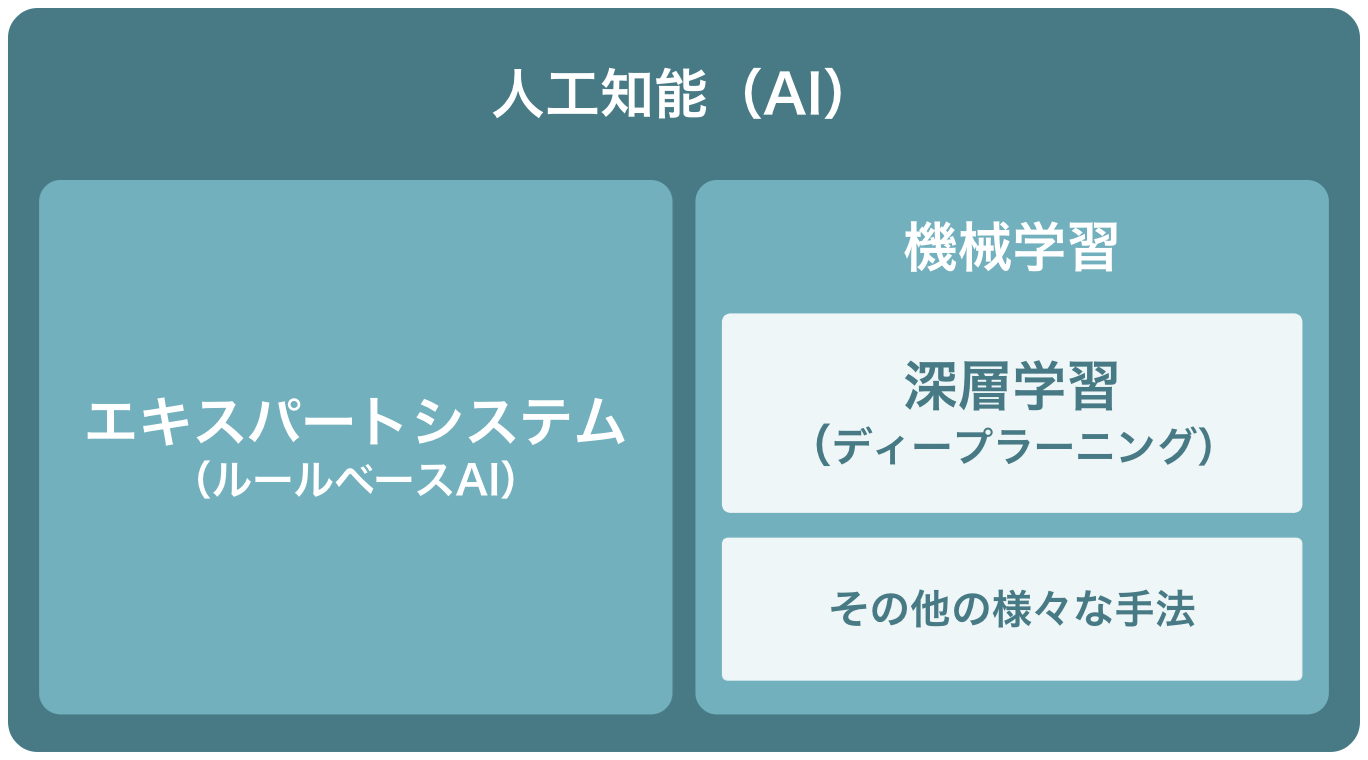
見てもらうとわかるように、AIというのが最も包括的な概念であり、機械学習はそのAIを構築するためのアプローチの1つということになる。そしてさらに、その機械学習の中の手法のひとつがディープラーニングだ。つまり、ディープラーニング以外の機械学習手法もたくさん存在しているということだ。
さらに、機械学習とは別のAI構築のアプローチとして「エキスパートシステム」がある。このあたりについては機械学習との関連性や研究の歴史も含めて、このあと解説する。
実は人工知能・AIの定義は定まっていない
そもそも「AIとはなんだろう?」という問いに対して、実は専門家の間でもその定義は定まりきっていない。以下は日本のAI研究者によるAIの定義をまとめたものだが、これだけのバリエーションがあるのだ。
| 研究者 | 定義 |
|---|---|
| 西田豊明(京都大学) | 「知能を持つメカ」ないしは「心を持つメカ」である |
| 長尾真(京都大学) | 人間の頭脳活動を極限までシミュレートするシステムである |
| 浅田稔(大阪大学) | 知能の定義が明確でないので、人工知能を明確に定義できない |
| 山口高平(慶應義塾大学) | 人の知的な振る舞いを模倣・支援・超越するための構成的システム |
| 松尾豊(東京大学) | 人工的につくられた人間のような知能、ないしはそれをつくる技術。人間のように知的であるとは、「気づくことができる」コンピュータ、つまり、データの中から特徴量を生成し、現象をモデル化することの出来るコンピュータという意味である |
以上を参考にしながら、とりあえずここでは人工知能を以下のようなものと考えておこう。
- 人間が行なっている次のような知能活動をコンピュータで再現したシステムである。
- 学習を行う:観測した事象やデータをもとに物事の関連性を解析して体系化・知識化すること。
- 推論を行う:学習した知識をもとに、新たな状況下でなんらかの判断や予測を行うこと。
- 意思決定を行う:推論した結果をもとに、これからとるべき最良の行動を判断すること。
まず推論とは、例えば、
- ある画像に写っているのが猫か犬かを判別する。
- あるコンビニにおいて梅おにぎりが今後1週間で何個売れるかを予測する。
- ある英語の文章を日本語の文章に翻訳する。
などが挙げられる。また、意思決定の例としては、
- 写真アルバムの中に猫の画像が多い人に、猫に関連する製品をおすすめする。
- 今後1週間の梅おにぎりの販売予測にもとづいて、発注数を決定する。
などが挙げられる。
そして以上のようなアウトプットを高精度に得るために重要になってくるのが「学習」のステップだ。推論および意思決定の根幹となる「学習」における「物事の関連性の体系化・知識化(しばしばモデル化と呼ばれる)」については、長年様々な研究が行われてきた。
形式知の学習に用いられたエキスパートシステム
近年のAIブームに先駆けて、実は1980年代にもAIブームと呼べる動きがあった。その引き金になったのがエキスパートシステムと呼ばれるアプローチだ。
エキスパートシステムは、専門家が頭の中で行なっている推論や意思決定のフローをシステム内で模倣・再現し、「AであればBである(IF-THENルール)」というような判断を繰り返すことで、最適解を導き出す。

このエキスパートシステムの最大の弱点は、「ルールが明確でないものはシステム化できない」という点だ。人間の知識には、言葉で明確に記述できる「形式値」と、経験と勘にもとづく「暗黙知」の2種類があるが、このうち「暗黙知」のほうはルールとして明確に書き下すことが非常に困難なのだ。だから、この暗黙知をシステム化できないエキスパートシステムでは知識獲得に限界があるということで、ブームも下火になってしまった。
暗黙知の獲得を可能にした機械学習
そんなエキスパートシステムで実現できなかった「熟練者の暗黙知の獲得」を可能にしたのが、事象を多角的かつ膨大に計測したビッグデータと、それをもとに「暗黙知の体系化」を行う技術である機械学習だ。
エキスパートシステムでは、人間が事象を理解した上で推論や意思決定のためのルールを記述する必要があったが、一方の機械学習では、推論・意思決定のもとになるデータとその結果をシステムに入力することで、自動的にルール(=モデル)を生成することができる。

例えば、画像に写っている動物が犬か猫かを判別するためのモデルを作成するためには、上記のような様々な犬と猫の画像を準備する。これらの画像には、写っている動物が犬なのか猫なのかを示す正解ラベルが付与されていて、機械学習は画像から正解ラベルを推論するためモデル(〇〇な特徴があれば猫、など)を生成する。
* 実際には、事前に人間が各動物の特徴のヒントを与える手法や、特徴の抽出自体もシステムに自動で行わせる手法など、様々なアプローチが存在する。
この機械学習によって精緻なモデルを生成するためには、学習の材料となるデータを可能な限りたくさん用意する必要がある。2010年代から昨今に至るAIブームが起こったのは、この機械学習の研究が進んだことに加え、デジタル産業の発展によって膨大なデジタルデータが利活用可能になったことが大きく寄与しているのだ。
なぜディープラーニングが注目されているのか
繰り返すが、ディープラーニングは機械学習の一手法でしかない。他にも様々な手法が存在している中で、なぜディープラーニングが注目されるのだろう? その理由を一言で表すとするならば、それは「精度」だ。
AIを使って画像に写っているものが何であるかを1,000個のカテゴリから判別するコンペティション(ImageNet Large Scale Visual Recognition Challenge)が2012年に行われた時に、従来手法で挑戦したチームが26%台の誤答率で競っている中、ディープラーニングを採用したチームの誤答率は16.7%と10%もの改善を実現した。その後も判別精度はどんどん改善され、2013年には誤答率は11.8%になり、2014年にはついに6.7%にまで低下しました。近年では、人間の判別能力を超える結果も得られている。
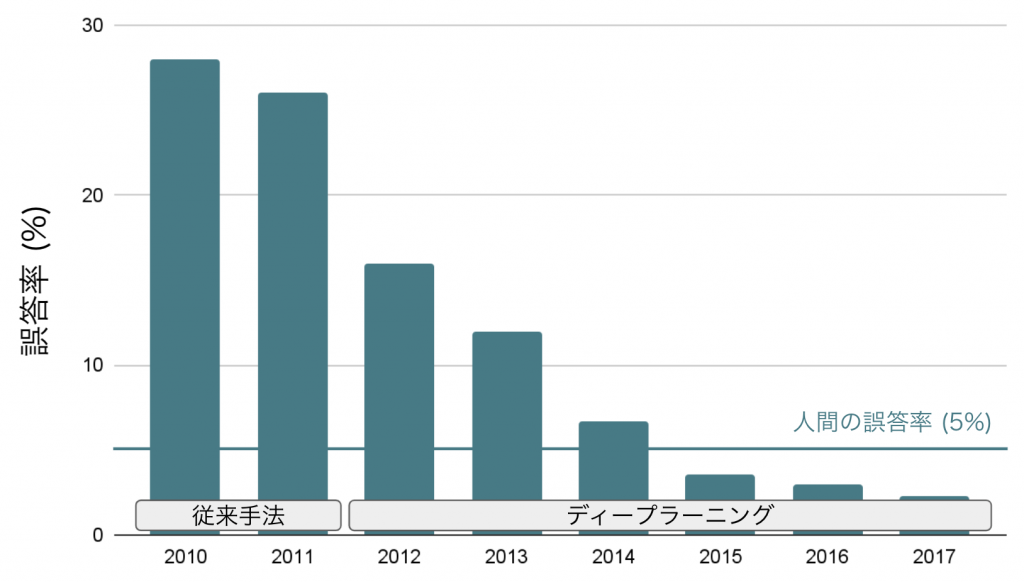
このことから、AI研究の権威である東京大学の松尾豊教授は、ディープラーニングを「人工知能における50年来のブレークスルー」と評している。
ただ、ディープラーニングは強力な機械学習手法ではあるが、それが常に最善の選択肢かというと、答えはNOだ。
実は前述した画像判別コンペティションに参加したチームは、学習ステップにおいて120万枚(平均1,200枚/カテゴリ)もの画像データを利用し、それら全てに正解ラベルが(人力で)付与されていた。つまり実用にあたっては、それと同等の質のデータを大量に準備できるかどうかが問題になる。この問題は数値データやテキストデータの解析でディープラーニングを活用する場合でも同様で、やはり膨大な学習データが必要となる。
だから、データ量がさほど多くない(数百〜数千)場合は、従来からあるシンプルな機械学習の手法(例えば重回帰分析など)の利用を検討することも必要となる。また推論・意思決定ルールが明確である場合は、エキスパートシステムを採用するのも依然として有効なアプローチとなる。
目的を達成するために適切なアプローチを選択することが重要
以上、今回はAIと機械学習とディープラーニングという、似て非なる3つの言葉の関係性やその歴史についてざっくり解説してみた。どうだろう、冒頭に掲げた次の文章の意味を、今ではなんとなく理解できるようになったのではないか?
「〇〇業向けの業務効率化アプリでは、機械学習を活用してAIを構築しますが、ディープラーニングではないアプローチを採用します。」
繰り返しになるが、機械学習にはディープラーニングではないアプローチもある。AIの導入にあたっては、機械学習やディープラーニングといった特定の手法を利用することを目的化せず、プロジェクトで成し遂げたいゴールを明確にした上で、それに適したアプローチを採用するように心がけることが重要だ。
この記事を書いたのは






















